Aufbau von Unicorn, dem Framework der Graph Search (Bild: Facebook)
Facebook hat das Einstufungssystem erklärt, das seiner Suche Graph Search zugrunde liegt. In einem Blogbeitrag behauptet Entwicklungsmanager Sriram Sankar sogar, das Ziel sei es, „die Zufriedenheit der Suchenden zu maximieren“. Dies dürfte sich darauf beziehen, dass sich nur ein bei den Anwendern beliebter Dienst auch durch Anzeigen monetarisieren lässt. Jedenfalls wird die Zufriedenheit in Click-Through-Raten und Normalized Discounted Cumulative Gain gemessen.
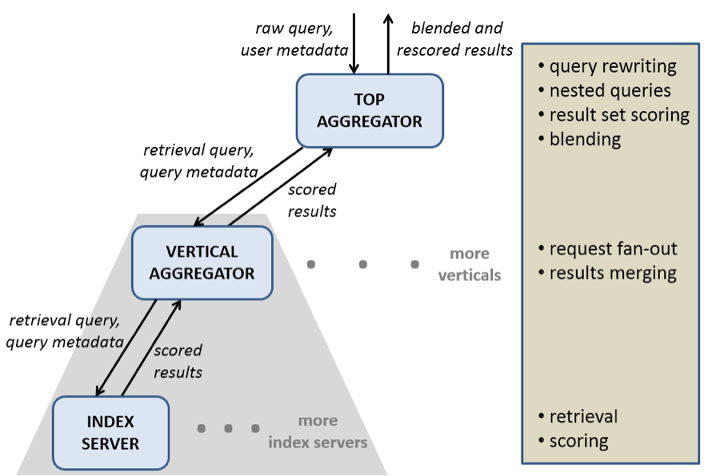
Die von Sankar gelieferte Beschreibung fällt dann deutlich technischer aus. Das für die Indizierung zuständige Framework heißt Unicorn. „Eine Unicorn-Instanz kann einen Index speichern, der zu groß für den Speicher einer einzelnen Maschine ist. Wir brechen den Index also in Bruchstücke auf, so dass jedes Bruchstück auf eine einzelne Maschine passt. Diese Maschinen heißen Index-Server. Abfragen an Unicorn werden an einen Vertical Aggregator gesendet, der wiederum die Abfrage an alle Index-Server weitersendet. Jeder Index-Server holt dann Objekte aus seinem Bruchstück und gibt sie zurück. Der Vertical Aggregator kombiniert sie zu einer Antwort auf die ursprüngliche Abfrage.“
Sankar bezeichnet Unicorn auch als „In-Memory-Datenbank mit Abfragesprache“. Jeder Datenobjekttyp – beispielsweise Nutzer, Seiten, Fotos – werde in einem separaten Unicorn-‚Regal‘ aufbewahrt, die alle unterschiedliche Ranking-Verfahren hätten. Der oberste Aggregator koordiniere die Aktivitäten dieser Subsysteme.
Für Abfragen werden logische Operatoren wie „und“ und „oder“ verwendet. Sankar erklärt allerdings, dass es bei einer kontextbezogenen Social Search oft sinnvoll sei, „und“ etwas schwächer zu werten und „oder“ sehr strikt zu beachten.
Unicorn gibt gefundene Objekte standardmäßig in einer statischen Reihenfolge zurück – also sortiert nach einer internen Identifikationsnummer. Die Beurteilung erfolgt nachträglich, und zwar für jedes Objekt separat. Graph Search teilt also jedem Treffer einen Punktwert für die aktuelle Anfrage zu, der nichts mit den Bewertungen anderer Treffer für die gleiche Anfrage zu tun hat.
Das führt aber zu schlechten Ergebnissen bei sehr breiten Abfragen. Beispielsweise bringt Sankar zufolge „Fotos von Facebook-Angestellten“ haufenweise Bilder von Mark Zuckerberg zutage – und wenige von anderen Mitarbeitern. Deshalb bewerte man auch Sets, denen viele sehr ähnliche Objekte angehören. Stellvertretend für ein solches Set erscheine dann nur eine Handvoll von als besonders interessant beurteilten Treffern – statt das komplette Set.
Für eine einzelne Suche führt Unicorn oft mehrere Anfragen durch, wenn die Bedingungen verschachtelt sind. Eine Suche nach „Restaurants, die Facebook-Mitarbeitern gefallen“ wird zum Beispiel in eine Suche nach Facebook-Mitarbeitern und anschließend in eine Suche nach Restaurantempfehlungen innerhalb der bereits gefundenen Objektgruppe unterteilt.
Um die Suchanfrage auszuwerten, verwendet Facebook Natural Language Parsing. Sucht jemand nach „Menschen in Sri“, empfiehlt dieser Parser aufgrund der Präposition „in“, Städte und Orte stark zu gewichten. So weiß Unicorn, dass es Treffer wie „Sri Lanka“ und „Srinagar“ höher werten muss als Personennamen wie „Sriram Sankar“.
[mit Material von Rachel King, ZDNet.com]
Tipp: Sind Sie ein SEO-Experte? Testen Sie Ihr Wissen – mit 15 Fragen auf silicon.de.
OutSystems-Studie: 62 Prozent der Befragten haben Sicherheits- und Governance-Bedenken bei Softwareentwicklung mit KI-Unterstützung.
Der Cybersecurity Report von Hornetsecurity stuft 2,3 Prozent der Inhalte gar als bösartig ein. Die…
Die Hintermänner haben es auf Zugangsdaten zu Microsoft Azure abgesehen. Die Kampagne ist bis mindestens…
Cloud-Plattform für elektronische Beschaffungsprozesse mit automatisierter Abwicklung elektronischer Rechnungen.
Mindestens eine Schwachstelle erlaubt eine Remotecodeausführung. Dem Entdecker zahlt Google eine besonders hohe Belohnung von…
Nur rund die Hälfte schaltet während der Feiertage komplett vom Job ab. Die anderen sind…
{kind=link}
{kind=link}