Big Data ist sicherlich einer der größten Mega-Trends im IT-Bereich. So gut wie alle großen Unternehmen beschäftigen sich eng mit dem Thema. Immer mehr mittelständische Firmen wollen ebenfalls auf Big Data setzen und sind auf der Suche nach der optimalen Umgebung dafür.
HPE bietet für Unternehmen aller Art eine Big Data-Umgebung im Rechenzentrum des Kunden als Service an . Dadurch können Unternehmen schnell und einfach auf Big Data setzen, und die Möglichkeiten der umfassenden Analyse für sich nutzbar machen. Big Data bietet für Unternehmen viele Vorteile: Neben dem Einsparen von Kosten, zum Beispiel durch Reduzierung von Retouren oder verbesserten Prozessen, lassen sich auch bessere und maßgeschneiderte Angebote für Kunden erstellen, und damit der Umsatz erhöhen. In jedem Unternehmen fallen haufenweise Daten aus verschiedenen Quellen an. Nur selten werden die Daten umfassend analysiert, und noch seltener werden sie in Beziehung miteinander gebracht.
Viele Unternehmen setzen auf Business Intelligence (BI). Bei Business Intelligence spielen genaue Daten eine wichtige Rolle. Die Daten werden sehr weit herunter gebrochen und kleinste Datenelemente werden umfassend analysiert. In Big Data-Umgebungen werden dagegen alle Daten erfasst, was ein deutlich höheres Datenvolumen verursacht. Die einzelnen Informationen spielen keine Rolle, sondern nur übergeordnete Informationen, Trends und gruppierte Informationen. Außerdem werden die Daten in Bezug zueinander gebracht, was wertvolle Informationen liefern kann, die bisher noch nicht vorliegen. Wenn Unternehmen eine Big Data-Infrastruktur aufbauen, geht es also darum zunächst alle verfügbaren Datenquellen zu inventarisieren, anzubinden und zu analysieren. Dazu ist ein Cluster notwendig, inklusive Betriebssystem, Software zur Analyse und Anbindung an die Datenquellen. Damit ein solches Projekt umgesetzt werden kann, ist ein kompetenter und zuverlässiger Partner notwendig.
Mit HPE Pointnext die IT im Unternehmen effizienter und sicherer nutzen
Der Nachteil von Big Data-Umgebungen ist deren Komplexität in Einrichtung, Verwaltung und Bedienung. Außerdem ist die Skalierung teuer. Hier hilft HPE mit seiner Private Big Data as a Service-Lösung (pBDaaS). Diese wird von HPE bereitgestellt, jedoch im eigenen Rechenzentrum des Unternehmens betrieben. Dadurch erhalten Kunden alle Vorteile von Big Data-Umgebungen in der Cloud in Verbindung mit den Vorteilen beim Betrieb einer eigenen Umgebung.
HPE gehört zu den größten und vertrauenswürdigsten Unternehmen in der IT-Branche. Das Unternehmen verfügt über globales und umfangreiches Know-how in der IT. Kunden können von diesem Know-how profitieren und die Verwaltung der IT mit HPE-Ressourcen ergänzen. Mit den Services von HPE Pointnext erhalten Unternehmen aller Art flexiblen Zugriff auf HPE-Fachwissen, das über geografische und technologische Gebiete hinweg konsistent ist. Die Unterstützung erfolgt in Kooperation mit vorhandenem IT-Personal, das dadurch entlastet und weitergebildet wird. Das gilt auch für den Big Data-Bereich. Hier kann HPE dabei helfen, eine optimale Analyse-Umgebung aufzubauen, und das bei überschaubaren Kosten.
Hadoop für Big Data nutzen
Eine der bekanntesten Lösungen im Big Data-Bereich ist sicherlich Hadoop. Die Analyse-Lösung steht über verschiedene Plattformen zur Verfügung und ist in der Lage riesige Datenmengen zu verarbeiten und zu analysieren. Leider hat die Umgebung den Nachteil sehr kompliziert in der Einrichtung zu sein. Die verschiedenen Datenquellen im Unternehmen werden selten aggregiert, sondern verschiedene Datenquellen werden auch durch verschiedene Hadoop-Installationen verwendet. Das mindert den Nutzen erheblich. Außerdem ist die mögliche Skalierbarkeit eingeschränkt, weil verschiedene Cluster mit Hadoop-Installationen im Einsatz sind.
Dazu kommt, dass für einen Hadoop-Cluster zahlreiche weitere Tools eingesetzt werden müssen. Diese ergänzen Hadoop um notwendige Funktionen. Allerdings sind die Tools unabhängig voneinander und haben einen unterschiedlichen Entwicklungsstand. Das resultiert zwangsläufig in Inkompatbibilitäten, und Leistungsproblemen. Außerdem ist die Umgebung nur sehr schwer installierbar und verwaltbar, da zahlreiche Zusatztools eingesetzt werden. Hier benötigen Unternehmen einiges an Know How oder einen Partner, der dieses Know How vorweisen kann.
Big Data selbst installieren
In den meisten Fällen installieren Unternehmen ihre Big Data-Lösung selbst im eigenen Rechenzentrum, oder betreiben Big Data in einer Public-Cloud-Umgebung, wie zum Beispiel Amazon Web Services oder Microsoft Azure. Natürlich haben Unternehmen bei der Installation der Umgebung im eigenen Netzwerk den Vorteil, dass sie vollständige Kontrolle über den Betrieb und die Serverdienste haben. Diese Kontrolle fehlt in einer Public-Cloud-Lösung. Allerdings ist dafür die Installation sehr komplex und benötigt ein entsprechendes Know How für die Installation von Diensten wie Hadoop und Co. Außerdem ist eine Testumgebung notwendig, in der neue Versionen und Tools, die zwangsläufig notwendig sind, ausführlich getestet werden können. Da ein lokal betriebener Cluster für Big Data keine einfache Umgebung ist, wird für eine produktive Umgebung eine entsprechende Projektplanung inklusive Projektmanagement notwendig sein. Auch das ist teuer und umständlich.
Wird die Big Data-Lösung im eigenen Rechenzentrum zur Verfügung gestellt, können Administratoren die Struktur der Cluster, die eingesetzte Hardware und viele Anpassungen an der eigentlichen Architektur vornehmen. Die Latenz ist wesentlich geringer, als die Analyse von Daten in der Cloud. Außerdem behalten Unternehmen jederzeit die Souveränität über ihre Daten. Dazu kommt die ständige lokale Verfügbarkeit und es lassen sich alle lokalen Serverdienste problemlos in die Analyse mit einbinden, ohne komplizierte Verbindungen in die Cloud schaffen zu müssen. Die Sicherheit der Analyse und die Compliance im Unternehmen ist ebenfalls gewährleistet, da das eigene IT-Personal immer Zugriff auf alle notwendigen Ressourcen der Big Data-Umgebung hat sowie auf die Daten, die analysiert werden.
Die Nachteile einer eigenen Big Data-Lösung liegen auf der Hand. Meistens werden die Kapazitäten überproportioniert, damit auch alle notwendigen Daten analysiert werden können. Das Unternehmen muss also mehr investieren als tatsächlich im Moment benötigt wird. Außerdem muss die Umgebung installiert, eingerichtet, getestet und ständig gewartet werden.
Big Data aus der Cloud nutzen
Als Alternative lassen sich Big Data-Lösungen auch in Public Cloud-Umgebungen betreiben. In solchen Umgebungen kümmert sich der Cloudanbieter um alles. Es müssen also keine eigenen Server installiert und verwaltet werden, sondern alles Notwendige kann direkt in der Cloud verwendet werden.
Werden Daten in der Cloud analysiert, sind die Vorteile der lokalen Verarbeitung die Nachteile der Verarbeitung in der Cloud. Die Nachteile der lokalen Verarbeitung stellen im Großen und Ganzen die Vorteile der Verarbeitung in der Cloud dar. Die Kapazität der Ressourcen lässt sich optimal gestalten, die komplette Abwicklung ist einfacher, leichter skalierbar und wesentlich flexibler.
Allerdings ist hier natürlich die Latenz stark schwankend, da nicht nur interne Netzwerkverbindungen zum Einsatz kommen, sondern auch Internetleitungen. Dazu kommen Probleme mit der Sicherheit, dem Datenschutz und der Transparenz der Umgebung. Es ist nicht klar, wer auf die einzelnen Komponenten zugreifen darf. Die Daten werden einem externen Anbieter anvertraut, und es lässt sich nur schwer nachvollziehen, ob dieser auf heikle Firmendaten zugreifen kann.
Private Big Data as a Service – Datenanalyse der nächsten Generation
Mit HPE Private Big Data as a Service erhalten Unternehmen die Einfachheit, Agilität und Kostenvorteile einer Public Cloud Lösung, mit den Leistungs- und Sicherheitsvorteilen von lokalen Big Data-Clustern. HPE bietet im Paket alle notwendige Soft- und Hardware als Dienst an.
Mit HPE Private Big Data as a Service (pBDaaS) können Unternehmen eine Big Data-Umgebung aufbauen und dabei die Vorteile der Public Cloud mit den Vorteilen einer lokalen Installation verbinden. Die Verwendung der Umgebung, aber auch die Bedienung, Analyse und der Aufbau entsprechen den Erfahrungen von Big Data in der Public Cloud. Die Umgebung ist schnell und einfach eingerichtet, leicht bedienbar und kann schnell und einfach skaliert werden. Die Vorteile beider Welten werden dadurch kombiniert, die enorme Flexibilität und Skalierbarkeit der Public Cloud und die Sicherheit und Kontrolle einer On-Premise-Lösung im eigenen Rechenzentrum.
Wächst der Bedarf an, kann die Umgebung ebenfalls skalieren. Die komplette Bereitstellung ist sehr flexibel und einfach gestaltet. Installiert, eingerichtet und verwaltet wird die Umgebung von HPE-Experten. Das bietet den Vorteil, dass die Umgebung sehr schnell einsatzbereit ist und optimal konfiguriert und betrieben wird. Da die Umgebung im Rechenzentrum beim Kunden betrieben wird, bleiben die Daten in der Hoheit des eigenen Unternehmens. Außerdem ist die Verarbeitungsgeschwindigkeit und der Datenabruf dadurch wesentlich effizienter.
Da HPE die Umgebung bereitstellt und Unternehmen nur das bezahlen, was sie benötigen, ist die Umgebung wesentlich einfacher planbar, auch was die Lizenzen und den Betrieb betrifft. Die komplette Hard- und Software verbleibt aber unter Kontrolle des Unternehmens, die Compliance wird optimal eingehalten und im Unternehmen wird für den Betrieb der Umgebung kein Fachpersonal benötigt. Die Verwendung der Umgebung „fühlt“ sich also an wie eine Analyse in der Cloud, mit den Vorteilen einer lokalen Analyse-Infrastruktur. Dazu gehört auch eine wesentlich geringere TCO.
Flexible Lizenzierung und Verwendung von pBDaas
Setzen Unternehmen auf Private Big Data as a Service von HPE erhalten sie eine flexible Lizenzierung. Zunächst wird pro Monat und Cluster ein fester Preis vereinbart. Das macht die Lizenzierung überschaubar und für Verantwortliche im Unternehmen besser planbar. Zusätzlich ist pro „Worker“, also Clusterknoten, ein variabler Preis fällig, abhängig von der verwendeten Datenmenge. Dadurch erhalten Unternehmen maximale Transparenz und Flexibilität. Es kann genau gesteuert werden, wie viele Hadoop-Cluster mit wie vielen Knoten eingesetzt werden sollen. Der Preis wird berechnet, weitere Lizenzen sind nicht notwendig. Dadurch erhalten Unternehmen eine ideale Planungssicherheit über die Kosten der Umgebung.
Unternehmen müssen nicht in Vorleistung gehen und auch keine Investitionen vornehmen, um auf Big Data zu setzen. Auch das Schulen von Administratoren und Entwicklern ist nicht notwendig, da alle Aufgaben zur Bereitstellung, Wartung und Operation von HPE übernommen werden. Da die Leistung der Umgebung optimal zur Verfügung gestellt wird, verschwenden Unternehmen weder Hardware noch Lizenzen. Durch den Betrieb im eigenen Rechenzentrum hat der Kunde optimale Voraussetzungen für beste Sicherheit und idealen Datenschutz.
Vom Standardausbau zur Enterprise-Umgebung
HPE bietet pBDaaS in verschiedenen Ausbaustufen an. Zunächst bietet sich eine Minimal-Konfiguration an. In diesem Fall wird die Standardausbaustufe verwendet, auch von Hadoop. Basierend auf der Verwendung der Umgebung, kann HPE die Lösung ausbauen, sodass mehr Leistung und Speicherkapazität zur Verfügung stehen.
Größere Unternehmen können Hadoop über pBDaaS auch basierend auch einer benutzerdefinierten Umgebung, also einem speziellen Use-Case nutzen. Auch hier kann natürlich jederzeit ein Ausbau der Umgebung stattfinden. Der Ausbau kann bis hin zu erweiterten pBDaas-Umgebungen führen, in denen auch Erweiterungen wie Vertica, Dataiku DSS und andere Lösungen integriert werden.
Architektur-Beispiele für pBDaaS und Hadoop
In der Basis-Konfiguration kann ein Hadoop-Cluster zum Beispiel aus drei Manager-Clusterknoten und drei Worker-Knoten bestehen. Reicht die Rechenkapazität nicht aus, können weitere Worker-Knoten hinzugefügt werden. Als Hardware kann zum Beispiel auf HPE ProLiant Server des Typs DL380 Gen9 oder Gen10 gesetzt werden, die über 256 GB Arbeitsspeicher verfügen sowie über 12x 1TB Speicherplatz. Als Software wird Red Hat Enterprise Linux mit HPE OneView & CMU gesetzt sowie auf die Hadoop Distribution von Hortonworks Enterprise oder Cloudera.
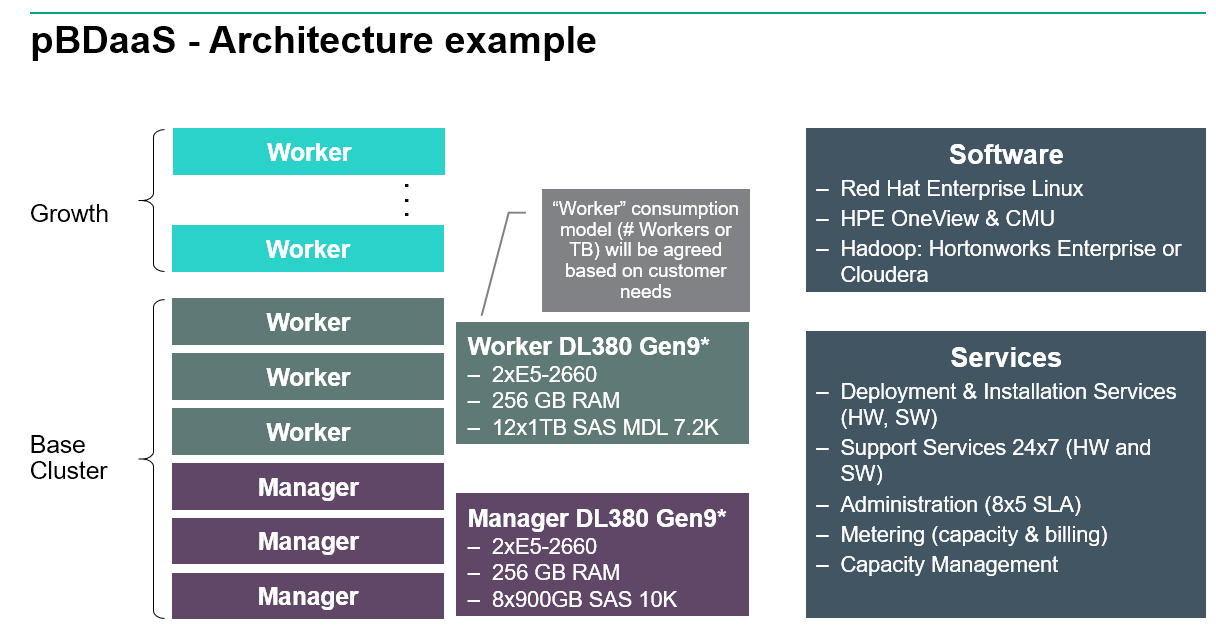 HPE bietet die passende Hard- und Software für Big Data-Umgebungen als Service an (Screenshot: HPE).
HPE bietet die passende Hard- und Software für Big Data-Umgebungen als Service an (Screenshot: HPE).
Als Dienstleistung bietet HPE zum pBDaaS-Vertrag die Bereitstellung, Installation und Einrichtung der Hard- und Software an. Außerdem erhalten Unternehmen 24×7 Support auf Hardware und Software. Auch die Verwaltung der Umgebung wird durch HPE übernommen, das gilt auch für die Planung und Ausweitung der Kapazität.
Durch das Buchen von pBDaaS erhalten Unternehmen den Vorteil, dass sie sich um keinerlei Komponenten und Lizenzen der Umgebung kümmern müssen. HPE stellt die Knoten für die Cluster als Hardware bereit, genauso wiedas Betriebssystem und die notwendige Software. Alle notwendigen Aufgaben um die Umgebung in Betrieb zu nehmen werden ebenfalls von HPE übernommen.
Fazit
Big Data gehört sicherlich zu den wichtigsten Trends für Unternehmen aller Art. Jedoch haben Big Data-Umgebungen den Nachteil sehr komplex in der Einrichtung und dem Betrieb zu sein. Der Aufbau ist teuer, erfordert einiges an Know How und muss gut geplant sein. HPE pBDaaS entlastet IT-Abteilungen und senkt die Kosten und Komplexität der Analyse von Daten.
Unternehmen erhalten eine skalierbare, flexible und optimal eingestellte Big Data-Umgebung, die jederzeit von HPE-Experten überwacht wird. Die Einführung von Big Data im Unternehmen wird dadurch vereinfacht, effizienter und sicherer. Das IT-Personal kann sich um andere Projekte kümmern, während die Big Data-Umgebung effizient eingesetzt wird. Verantwortliche im Unternehmen haben die Kosten besser im Griff, da keine teuren Investitionen in Hard- und Software notwendig sind. Alle Kosten werden durch eine monatliche Zahlung abgedeckt, die wesentlich einfacher planbar ist.
![]()
