
Gastbeitrag Service-Orientierung gilt ein wenig als conditio sine qua non in der heutigen Wirtschaftswelt. Ohne Service läuft nichts. Dabei werden Kundenanfragen typischerweise in Form von Tickets aufgenommen und be- bzw. verarbeitet. Entscheidend für die schnelle qualifizierte Bearbeitung sind Kategorisierung und sachgerechte Weiterleitung. Sie bilden die entscheidenden Stellgrößen für eine zügige Bearbeitung und damit positive Wertschätzung seitens Nutzer und Kunden.
 Bianca Hille und Thomas Weimar, die Autoren dieses Beitrags, sind bei BTC beschäftigt. Die BTC Business Technology Consulting AG ist eines der führenden IT-Consulting-Unternehmen in Deutschland mit Niederlassungen in China, Japan, Polen, Rumänien, der Schweiz, der Türkei und den USA. Das Unternehmen mit mehr als 1.800 Mitarbeitern und Hauptsitz in Oldenburg ist Partner von SAP und Microsoft. BTC erzielte in 2019 einen Umsatz von 213 Mio. Euro (Bild: BTC).
Bianca Hille und Thomas Weimar, die Autoren dieses Beitrags, sind bei BTC beschäftigt. Die BTC Business Technology Consulting AG ist eines der führenden IT-Consulting-Unternehmen in Deutschland mit Niederlassungen in China, Japan, Polen, Rumänien, der Schweiz, der Türkei und den USA. Das Unternehmen mit mehr als 1.800 Mitarbeitern und Hauptsitz in Oldenburg ist Partner von SAP und Microsoft. BTC erzielte in 2019 einen Umsatz von 213 Mio. Euro (Bild: BTC).
Die Dispatcher im 1st-Level-Support werden deshalb jede Entlastung zu schätzen wissen, ankommende Tickets schneller bearbeiten zu können. Im Rahmen erster Automatisierungsaktivitäten wurde – und wird heute häufig noch – mit regelbasierten Werkzeugen experimentiert, um die Effizienz des Service-Desk zu steigern. In einer Welt mit vornehmlich festen Abläufen und Tickets mit überschaubarem Informationsgehalt sind diese Werkzeuge eine vielversprechende Hilfe. Wenn jedoch Dynamik und Komplexität das charakteristische Merkmale der zu betreuenden Umgebung ist, stoßen sie schnell an ihre Grenzen. Zum einen müsste das Regelwerk ausufernde Verhaltensvorschriften und das Wörterbuch immer mehr Begriffe aufnehmen. Zum anderen sind die Ticket-Inhalte im Allgemeinen recht frei verfasst und lassen sich nur bedingt normieren.
Deutlich höher ist das Leistungsversprechen und -potenzial der Künstlichen Intelligenz (KI) für Support und Ticketbearbeitung zu bewerten. Mit Hilfe maschinellen Lernens – also der KI-Teildisziplin ML (Maschine Learning) lassen sich Modelle entwickeln. Diese verstehen die eingehenden unstrukturierten Tickets und klassifizieren die Nachricht automatisiert, um sie im Anschluss selbstständig einem verantwortlichen Service-Team zuzuordnen. Ihr Verständnis zum jeweiligen Aufgabenfeld „trainieren“ die Modelle anhand historischer Daten. Konkret werden hier Techniken des ML-Teilbereichs Deep Learning (DL) herangezogen, die auf Grundlage mehrschichtiger neuronaler Netze, Datenbestände nach Muster durchforsten und Wissen extrahieren.
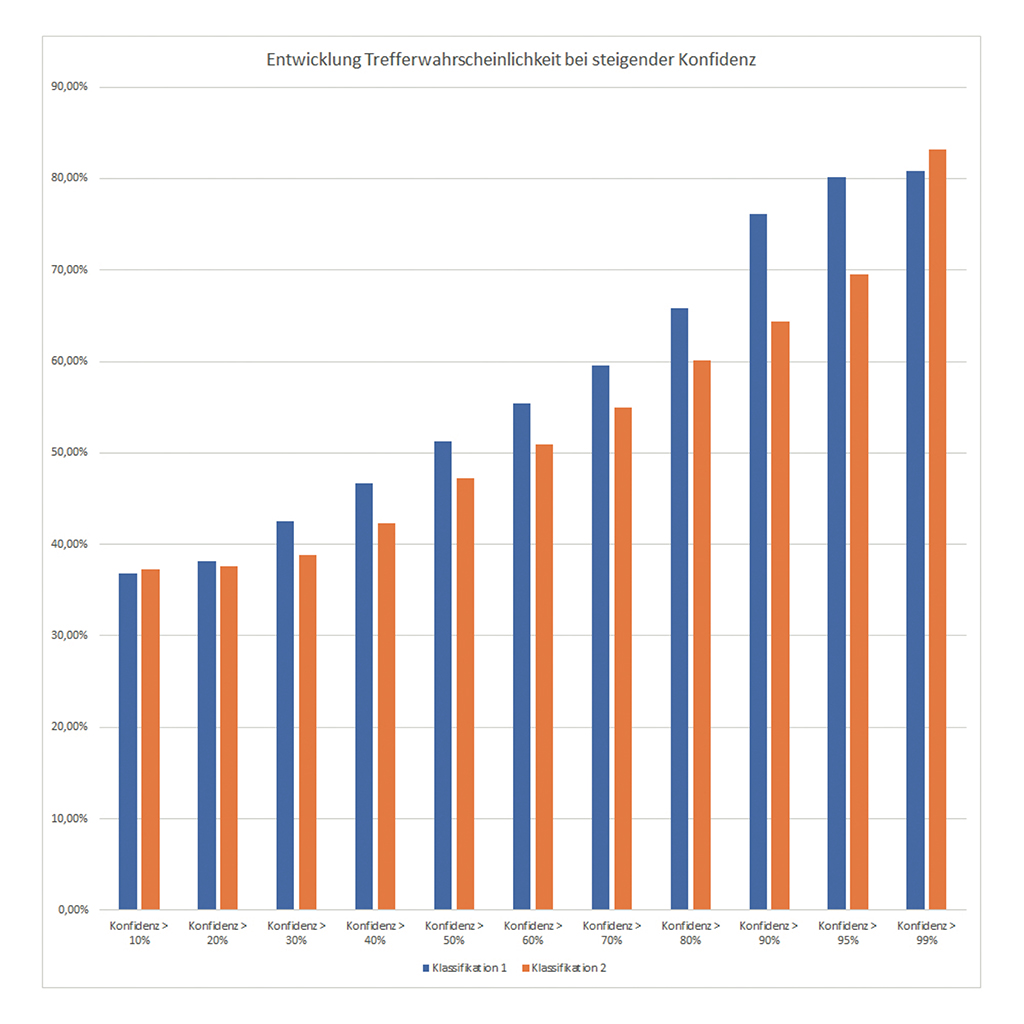 Entwicklung der Trefferquote bei steigender Konfidenz des Labels Arbeitsgruppe (Bild: BTC)
Entwicklung der Trefferquote bei steigender Konfidenz des Labels Arbeitsgruppe (Bild: BTC)
Vorteilhaft ist des Weiteren, dass die Einstiegshürde in die KI/ML-Welt deutlich gesenkt ist. Unternehmen sind nicht mehr gezwungen, großartig in eigene Expertise und IT-Ressourcen zu investieren. Sie können sich stattdessen aus einem wachsenden Tool-Angebot bedienen, dessen Vertreter dediziert für den Einsatz in ausgewählten Anwendungsdomänen konzipiert sind, beispielsweise ein Ticketsystem von Zendesk, das effiziente Lösungen für die Ticketbearbeitung bietet.
SAP stellt beispielsweise mit Service Ticket Intelligence (STI) eine Anwendung bereit, die auf Grundlage von Deep Learning-Techniken den Aufbau einer selbstgesteuerten Ticketbearbeitung unterstützt. Sobald ein Service-Ticket eintrifft, ordnet ein Algorithmus (Classification Engine) diesem automatisch eine Priorität und die passende Arbeitsgruppe zu. Gleichzeitig wird der Dringlichkeitsgrad anhand der Eingabe der Kundenanfrage festgelegt. Der Supportmitarbeiter erkennt also sofort, welche Anfrage die höchste Bearbeitungspriorität besitzt. Parallel dazu analysiert ein zweiter Algorithmus (Recommendation Engine) den unstrukturierten Text eines eintreffenden Tickets und unterbreitet Empfehlungen für Lösungsansätze aus vergleichbaren, bereits behandelten Anfragen. Die Mitarbeiter am Service-Desk können sich folglich direkt mit der Beantwortung eines gemeldeten Problems befassen, ohne erst mühsam Wissensdatenbanken manuell durchforsten zu müssen.
Das klingt vielversprechend. Mit welchem Aufwand ist aber das Training von STI verbunden? Und – noch wesentlicher – ist die Anwendung tatsächlich in der Lage, das Leistungsversprechen belastbar einzulösen? Um die Antwort vorwegzunehmen: Die Ergebnisse der ersten Trainingsrunden und Testläufe mit der STI-Software, die BTC für die Ticket-Bearbeitung in ihrem Kerngeschäft IT-Betreuung und Managed Services in Angriff nahm, sind vielversprechend.
Das technische Aufsetzen der Anwendung geht vergleichsweise leicht von der Hand, da sie als Cloud Foundry-verwalteter Service der SCP (SAP Cloud Platform) bereitgestellt wird. Sie bietet von Haus aus eine Schnittstelle (REST API), die die oben erwähnten beiden Aufgaben abdeckt. Gemäß ihrer Ausrichtung nutzt die Classification Engine hierzu überwachtes Lernen, während die Recommendation Engine auf unüberwachtem Lernen basiert (vergl. Textkasten). Um die Arbeit der „Trainer“ in Unternehmen bequemer zu gestalten, hat BTC ergänzend eine grafische Bedien- und Administrationsoberfläche für die STI-Funktionen implementiert. Neben der grundsätzlich einfacheren Bedienung beschleunigt diese gleichzeitig den Schulungsablauf, da beispielsweise Lerndatensätze en bloc übermittelt werden und nicht mehr einzeln manuell hochgeladen werden müssen.
Für die konkrete Modellerstellung wird ein Trainingsdatensatz an die STI gesendet. Wie im realen Leben korreliert das spätere Leistungspotenzial von der konsequenten Trainingsdurchführung – im betrachteten Anwendungsfall sind also Qualität, Zusammenstellung und der Umfang der Daten entscheidend. Empfehlungen der SAP zufolge sollten für das Training eines Modells pro Label 1000 Datensätze verwendet werden. Ein Label bezeichnet eine Ausprägung eines Ausgabewertes, etwa die Ticketkategorie oder Links zu Lösungsdokumenten. Naheliegend ist, dass die Datensätze keine veralteten oder fehlerbehafteten Informationen etwa über bereits aufgelöste Arbeitsgruppen im 1st-Level-Support enthalten dürfen. Auch sollten sie in ausreichender Anzahl möglichst ausgewogen die Vielfalt der Anfragenachrichten widerspiegeln. Um die Präzision und Korrektheit der Berechnungen bewerten zu können, gibt die STI zu jedem Ergebnis der Klassifizierung und Empfehlung der trainierten Modelle den Konfidenzwert aus – also das Sicherheitsmaß, mit der das Ergebnis zutrifft.
Trainingsmethodik
Allgemein lassen sich die gängigen „Trainingsmethoden“ des maschinellen Lernens den drei Kategorien „überwachtes“, „unüberwachtes“ und „bestärkendes“ Lernen zuordnen. Im Fall des überwachten Lernens – englisch Supervised Learning – werden Trainingsdaten benötigt, die aus Eingabe-Parametern sowie korrekten Ausgabedaten bestehen. Aus diesen Paaren wird ein Modell erstellt, das Assoziationen herstellen kann und für unbekannte Eingabewerte passende Ausgabewerte definiert. Typischerweise wird diese Lernform vornehmlich für zuordnende, klassifizierende Aufgaben oder Regressionsprobleme herangezogen. Beim unüberwachten Lernen – dem Unsupervised Learning – stehen im Gegensatz zum „überwachten“ Pendant lediglich Eingabewerte zur Verfügung. Der Algorithmus extrahiert folglich Strukturen und Zusammenhänge aus den Ähnlichkeiten der Input-Muster, in dem er statistische Verfahren wie Clustering einsetzt. Diese Stärken kann das Modell insbesondere bei Fragen der Segmentierung, Kategorisierung oder Empfehlungsausgabe ausspielen. „Bestärkendes“ Lernen (Reinforcement Learning) verbessert wiederum die Leistung von Navigationssystemen oder Robotik. durch „Belohnen“. Verkürzt formuliert interagiert hier ein Agent (der Modellalgorithmus) mit seiner Umwelt und abhängig von der Belohnungshöhe einer Aktion „erlernt“ er die vielversprechendste Zielführung.
Bei der zu Recht in manchen Einsatzszenarien (z.B. Bilderkennung) mit Vorsicht zu betrachtende Kenngröße, zeigt die automatisierte Ticket-Bearbeitung, dass sie einen realen Mehrwert bringt. So erreichte das trainierte Modell der Classification Engine bei einem ersten Test mit circa 7000 Trainingsdatensätzen bei den Ausgabe-Labels „Arbeitsgruppe“ und „Priorität“ im Vergleich zu „historischen“ Ergebnissen zunächst Trefferquoten von rund 40% bei den Arbeitsgruppen und 90% bei der Priorität. Wird bei den Arbeitsgruppen zusätzlich die Höhe des Konfidenzwerts eingebunden – im Testfalle 95% – verdoppelte sich die Trefferquote (siehe Abbildung). Nach weiteren Testläufen weist das mit 24317 Datensätzen trainierte Modell Quoten von 80% bei 20 verschiedenen Arbeitsgruppen und 90% bei vier verschiedenen Prioritäten auf. Für Recommendation Engine wurde zumindest in Ansätzen gleichfalls ein Testlauf entworfen. Dabei behalf man sich eines Tricks, um neue Eingaben zu simulieren. Es wurde jedes fünfte Wort der Tickets in der Trainingsdatei gelöscht und im Anschluss kontrolliert, ob noch immer der korrekte Lösungsvorschlag ausgegeben wurde. Eine Trefferquote von 85% lassen auf ein hohes Leistungspotenzial schließen. Die Reaktionsgüte auf tatsächlich unbekannte Ticketnachrichten lässt sich indes erst im realen Einsatz verlässlich ermitteln.
In Summe legen die Testergebnisse mit der STI nahe, dass der Einsatz von Deep Learning im Servicedesk eine deutlich beschleunigte Ticket-Bearbeitung und Prozessdurchführung verspricht. In Kombination mit dem Konfidenzwert zahlt die Anwendung bereits heute in die tiefe Automatisierung eines selbstgesteuerten Kundenservices ein. Wird beispielsweise Konfidenz 99% erreicht, lässt sich ein ankommendes Ticket direkt an die passende Arbeitsgruppe weiterleiten, während in den anderen Fällen der Dispatcher im 1st-Level-Support den Vorgang noch kontrolliert. Empfehlungen der Recommendation Engine helfen, die Erstlösungsquote auf Seiten des 1st-Level zu erhöhen. Zugleich weisen die Vorschläge auf neue, vielversprechende Lösungsalternativen hin, die zuvor eher unerkannt waren. Ungeachtet aller Güte sollte bei dem produktiven Betrieb der Deep Learning-Modelle in der Ticketverarbeitung das Training nicht vernachlässigt werden. Um dem schleichenden Trägheitsprozess vorzubeugen, empfiehlt sich, insbesondere für Modelle der Supervised Learning-Kategorie in regelmäßigen Abständen neue Trainingsrunden zur weiteren Optimierung anzusetzen.

Neueste Kommentare
Noch keine Kommentare zu Intelligenter Vorsatz: KI beschleunigt Ticket-Bearbeitung
Kommentar hinzufügenVielen Dank für Ihren Kommentar.
Ihr Kommentar wurde gespeichert und wartet auf Moderation.